Die Herausforderung: Anomalien in Energieverbrauchsprofilen
Im Rahmen des Forschungsprojektes PROGRESSUS, an dem eine Arbeitsgruppe von Ingenics Digital von 01.04.2020 bis 31.09.2023 beteiligt war, haben wir (unter anderem der Autor dieser Notiz) nicht nur die Optimierung des Paketroutings in der Kontrollebene von Software-Defined Networking erarbeitet, sondern auch eine Untersuchung durchgeführt, inwieweit maschinelles Lernen (machine learning, ML) zur Erkennung von Anomalien in Energieverbrauchsprofilen geeignet ist. Dazu setzten wir hauptsächlich auf Verfahren des bestärkenden Lernens, um die Effektivität eines Energiemanagementsystems zu verbessern. Außerdem verwendeten wir Algorithmen des maschinellen Lernens, um die Zeit, Menge, Dauer und den verfügbaren Strompuffer vorherzusagen und diese Daten an übergeordnete Netze weiterzuleiten.
Hintergrund
Im EU-Forschungsprojekt PROGRESSUS wurden neue Konzepte, Technologien und Komponenten untersucht, welche die Integration von erneuerbaren Energiequellen und -speichern kombiniert mit einem intelligenten Energiemanagement ermöglichen. Dies soll den Bedarf der Primärenergie sowie der CO2-Emissionen reduzieren und eine dezentrale Energieinfrastruktur vorantreiben. Die Wandlung des Energienetzes vom reinen Verteilnetz hin zum Smart Grid ist ein unverzichtbarer Schritt, um die Klimaschutzziele zu erreichen und um den Bedarf an fossilen Energieträgern deutlich zu reduzieren. Wesentliche Elemente dieses Wandels sind die Erweiterung des Energieversorgungsnetzwerks um folgende Komponenten:
- Zustandserfassung in Echtzeit
- sichere Kommunikationsverfahren für den Austausch von Zustands-, Kontroll- und Steuerungsdaten sowie
- die effiziente Wandlung elektrischer Energie zur Verknüpfung von Verbrauchern, Speichern und Energiequellen.
Für PROGRESSUS wurde das Anwendungsbeispiel einer Ladeinfrastruktur für Elektrofahrzeuge gewählt (Abb. 1). Sie besteht aus einer lokalen, miteinander vernetzten Gruppe von Ladestationen, die ein Mikrogrid bildet, das an einem Übergabepunkt mit dem Verteilnetz verbunden ist. Gleichzeitig sind die Ladesäulen in einem Kommunikationsnetzwerk zusammengeschlossen.
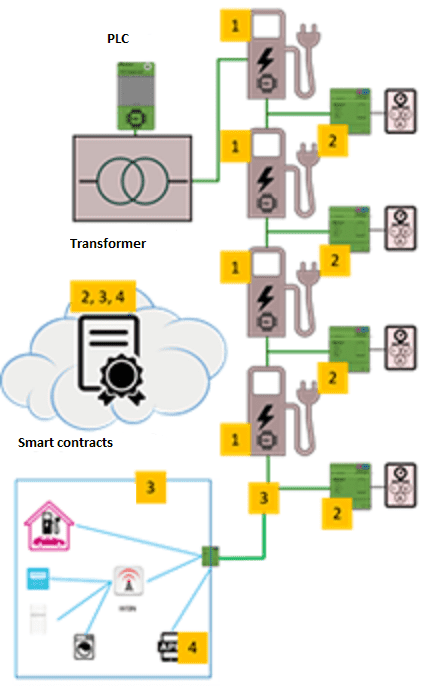
Abb. 1: Schematische Darstellung der Ladeinfrastruktur für E-Fahrzeuge. Gezeigt sind:
- vier Ladesäulen (1) mit Speicherbatterie, bidirektionalem DC/DC-Wandler, integrierter Leistungskomponente und Stromsensor,
- eine Plattform (2) für Mehrwertdienste mit dezentralisiertem Energiemanagement und Sicherheitschip,
- eine sichere Netzwerkverwaltung (3) mit dynamischem Netzwerkmanagement sowie einer
- Monitoring-Einheit (4) für die Statusüberwachung von Netzwerkknoten u.a. Smart contracts für den Stromhandel werden von den Komponenten 2, 3 und 4 ausgehandelt. Die Ladeinfrastruktur ist gemeinsames Arbeitsergebnis aller an PROGRESSUS beteiligten Partner.
Anwendungsfälle
Wir haben den Einsatz von Algorithmen des maschinellen Lernens für zwei Einsatzfälle analysiert. Die auf maschinellem Lernen basierende Fehler- bzw. Mustererkennung in intelligenten Netzen ist ein wachsendes Forschungsgebiet. Es gibt verschiedene Ansätze von maschinellem Lernen: überwachtes, unüberwachtes und bestärkendes Lernen.
Energievorhersage
Die Energieprognose in einem Mikronetz beruht auf gesammelten Daten von jedem Gerät, das an das Netz angeschlossen ist. Das Energieprofil eines Geräts besteht aus einem Datensatz für dieses Gerät. Eine Sammlung solcher Energieprofile wurde sowohl für das Training als auch die Validierung eines neuronalen Netzes unter Einsatz von Algorithmen des maschinellen Lernens verwendet. Dieses so trainierte Netz kann dann zur Vorhersage des Energiebedarfs von Verbrauchernetzen verwendet werden. Ein Kommunikationsknotenpunkt überwacht die Daten aller angeschlossenen Geräte und trainiert ein neuronales Netz, mit dem z. B. die Betreiber von Energienetzen Anpassungen an ihre Energieproduktion vornehmen können.
Erkennung von Gerätefehlfunktionen und vorbeugende Wartung
Wir haben einen intelligenten Controller entwickelt, der neben anderem auch Anomalien im Verbrauchsverhalten der Geräte durch unüberwachtes Lernen erkennen sollte. Zur Gruppierung ähnlicher Datenpunkte wurde Clustering eingesetzt. Andere Algorithmen suchten nach Anomalien, um Datenpunkte zu identifizieren, die erheblich vom erwarteten Verhalten des Netzes abweichen. Die Überwachung der Energieprofile von Geräten sollte die Vorhersage ermöglichen, wann ein Gerät wahrscheinlich ausfallen könnte, weil sein Energieverbrauch entweder z.B. aufgrund eines Defekts zu niedrig oder z.B. kurz vor dem Ausfall zu hoch ist. Die Überwachung auf Fehlfunktionen von Geräten beinhaltet auch das Senden unangemessener oder ungültiger Daten oder die Erkennung von Eindringlingen, z.B. Einschleusung einer doppelten Geräte-ID.
Die Methodik
Unsere Methodik basiert auf einem neuen Ansatz zur Erkennung von Anomalien in Energieverbrauchsprofilen unter Verwendung der Mahalanobis-Distanz und eines 1D CNN-Autoencoders. 1D bedeutet dabei "eindimensional" und CNN steht für convolutional neuronal network, also insgesamt ist es ein eindimensionaler Faltungs-Autoencoder.
Der Grund für dessen Einsatz ist der, dass die Mahalanobis-Distanzklassifizierung am besten für multivariate, normalverteilte Daten geeignet ist. Viele Verbrauchsprofile weisen jedoch Sprünge im Stromverbrauch auf, sobald Geräte eingeschaltet werden. Um diese Nichtlinearität zu modellieren, war ein unterstützendes neuronales Netzwerkmodell nötig. Wir haben dazu mehrere verschiedene neuronale Netzwerkarchitekturen geprüft, von denen sich der 1D-CNN-Autoencoder als geeignet erwies.
Die Mahalanobis-Distanz
Die Mahalanobis-Distanz wird verwendet, um den Abstand zwischen jedem Datenpunkt und dem Mittelwert eines Datensatzes zu berechnen. Im Gegensatz zum Euklidischen Abstand, der davon ausgeht, dass die Daten normalverteilt und unabhängig sind, berücksichtigt der Mahalanobis-Abstand die Korrelation zwischen verschiedenen Merkmalen und die Kovarianz der Referenzdaten. Die Mahalanobis-Distanz wird auf der Grundlage des Mittelwerts und der Kovarianz der Trainingsdaten berechnet. Zunächst wird eine Reihe von Referenzpunkten gesammelt, die typische Energieverbrauchsprofile darstellen. Dann wird die Kovarianzmatrix der Merkmale in den Referenzpunkten berechnet. Die Kovarianzmatrix beschreibt die Korrelation zwischen verschiedenen Merkmalen, in unserem Fall ein 1-Minuten-Intervall eines über eine Stunde gemessenen Energieprofils.
Das eindimensionale neuronales Faltungsnetzwerk
Ein Autoencoder ist ein neuronales Netz, das lernen kann, Eingabedaten zu rekonstruieren, indem es sie in eine Darstellung von niedrigerer Dimension kodiert und dann wieder in ihre ursprüngliche Form dekodiert. Wird ein Autoencoder auf normale Zeitreihendaten trainiert, kann er lernen, die Muster und Abhängigkeiten in den Daten zu erfassen und sie mit geringem Fehler zu rekonstruieren. In unserem Kontext sollte er die normalen Energieverbrauchsmuster erlernen und Anomalien erkennen, die erheblich von den erlernten Mustern abweichen.
Kombination beider Methoden und Bewertung
Bei anomalen Zeitreihendaten ist es für den Autoencoder schwieriger, diese genau zu rekonstruieren, was zu einem höheren Rekonstruktionsfehler führt. Die Kovarianzmatrizen jeder Klasse müssen zunächst geschätzt werden. Dies macht man mit Proben, von denen die Klassenzugehörigkeit bekannt ist. Nach der Berechnung der Mahalanobis-Distanz zwischen einem Testpunkt und jeder Klasse wird der Testpunkt dann der Klasse zugeordnet, für die die Mahalanobis-Distanz am geringsten ist. Wenn eine Testprobe eine hohe Mahalanobis-Distanz aufweist, ist es wahrscheinlich eine Anomalie, da sie erheblich von der vom Autoencoder rekonstruierten Normalverteilung abweicht. Durch die Kombination der Mahalanobis-Distanz mit dem Autoencoder fügten wir eine zusätzliche Ebene hinzu, mit der Anomalien in Zeitreihendaten mit wesentlich höherer Genauigkeit erkannt werden können.
Die Modelle wurden während 100 Epochen trainiert unter Verwendung eines großen Datensatzes mit einer Stapelgröße von 4096 (62^2) sowie einer angepassten Lernrate. Dann wurde das Training vorzeitig gestoppt, um eine Überanpassung zu vermeiden. Während des Modelltrainings wurde die Mahalanobis-Distanz zwischen den Originaldaten und den rekonstruierten Daten für jede Datenprobe im Trainings- und Validierungsdatensatz berechnet, anschließend der Mittelwert für jede Epoche, der später für die Modell-Bewertung verwendet wurde (Abb. 2).
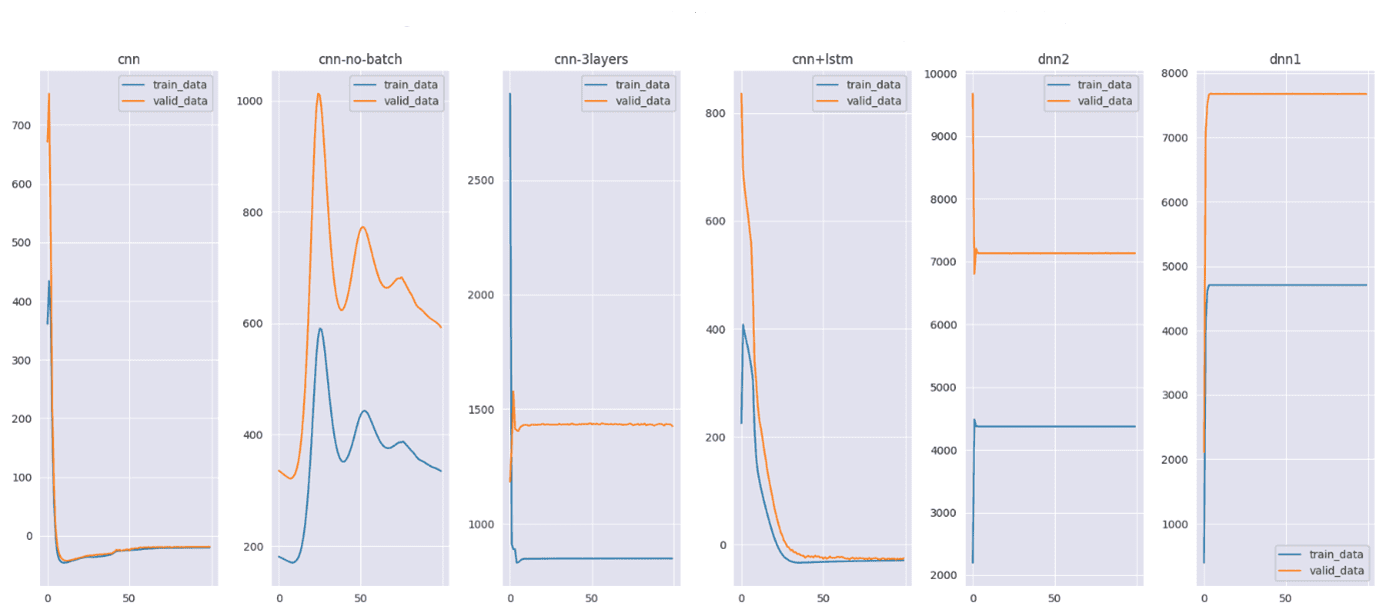
Abb. 2: Vergleichende Darstellung der Performanz verschiedener Modelle, welche die Mahalanobis-Distanz als ein Maß auf den Unterschied zwischen den eingegebenen und den rekonstruierten Energieprofilbeispielen verwenden. Dieser Unterschied sollte möglichst gering sein, was anzeigt, dass die Rekonstruktion der Daten durch das Modell sehr nahe an den ursprünglich eingegebenen Originaldaten liegt. Dargestellt ist der Anteil des mittleren Mahalanobis-Distanzfehlers in Abhängigkeit von den Trainingsepochen. Die blauen Linien zeigen die Mahalanobis-Distanz für die Trainingsdaten, die orangefarbenen für die Validierungsdaten. Die x-Achse gibt die Anzahl der Trainingsepochen an, die y-Achse repräsentiert die Mahalanobis-Distanz.
Die meisten Modelle, darunter das CNN (Convolutional Neuronal Network), das CNN mit langem Kurzzeitgedächtnis (CNN+LSTM) sowie das Deep Neural network (DNN) zeigen für die Mahalanobis-Distanz eine schnelle Abnahme für sowohl Trainings- als auch Validierungsdaten während der frühen Trainingsepochen, was auf schnelle Konvergenz hinweist. Die höheren Ausschläge im zweiten Diagramm sind auf einen weniger stabilen Lernprozess zurückzuführen. CNN+LSTM und DNN werden bei höheren Mahalanobis-Distanzwerten stabiler, was möglicherweise auf Überanpassung oder nicht ausreichende Modellkomplexität für die Daten hinweist. Das Modell 1D-CNN mit niedriger Modellkomplexität im ersten Diagramm dagegen zeigt schnelle Konvergenz, stabile Performanz, eine niedrige Fehlerrate bei der Datenrekonstruktion. Deshalb ist es im Vergleich zu den komplexeren und instabileren Modellen wie CNN-LSTM oder DNN das geeignetste Modell.
Wenn die Mahalanobis-Distanz für die Originaldaten und die rekonstruierten Daten während des Trainings gleich oder minimal ist, kann daraus geschlossen werden, dass das jeweilige Modell gut verallgemeinert und an die Trainingsdaten weder über- noch unterangepasst ist. Anschließend wurde eine Wahrheitsmatrix erstellt, um die Genauigkeit des 1D-CNN-Autoencoders zu bewerten. Dieses Modell hat 99 % der testweise vorgegebenen (also zu findenden) Anomalien mit weniger als 1,5 % falsch positiven Ergebnissen korrekt identifiziert (Abb. 3).
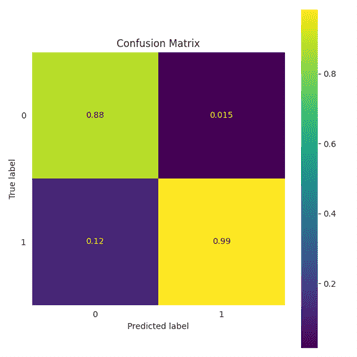
Abb. 3: Wahrheitsmatrix für die Mahalanobis-Distanz auf den Validierungsdatensatz. Die Matrix ist in vier Felder eingeteilt: Links oben grün: Anzahl der korrekt erkannten nicht anomalen Werte in Prozent (der Wert 0.88 entspricht 88 %), rechts unten gelb: Anzahl der korrekt erkannten Anomalien (99 %), daneben in blau die falsch negativen mit 12 % sowie die falsch positiven mit 1,5 %. Die Ergebnisse sind auf die Vorhersage normalisiert.
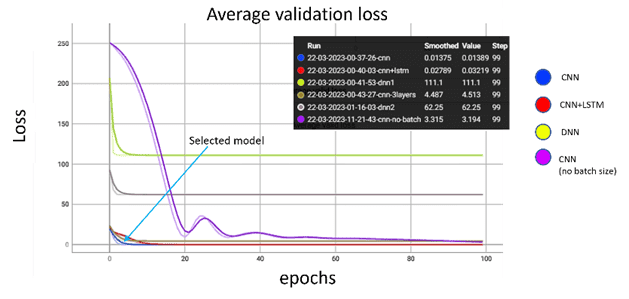
Eine weitere Bewertungsmethode, die für die Bewertung der Modellleistung gewählt wurde, ist die manuelle Einführung von Gauß-Rauschen in die Ausreißerdaten, die zuvor aus den Trainingsdaten gefiltert wurden. Um Anomalien zu erkennen und die Genauigkeit des Modells zu bewerten, wurden die erzeugten Ausreißer gruppiert und für alle Proben mit einem wahren Label versehen (Anomalie). Anschließend wurden die rekonstruierten Stichproben verwendet, um das vorhergesagte Label auf der Grundlage eines zuvor ausgewählten Abstandsschwellenwerts zu bestimmen. Bei der Anwendung des Modells auf Daten, die nur Anomalien enthalten, zeigt das ausgewählte Modell eine Genauigkeit von 92 % bei der Erkennung von Anomalien mit einer Falsch-Negativ-Rate von 7 %. Auch bei der Lernleistung schneidet der ausgewählte 1D-CNN-Autoencoder sehr gut ab (Abb. 4).
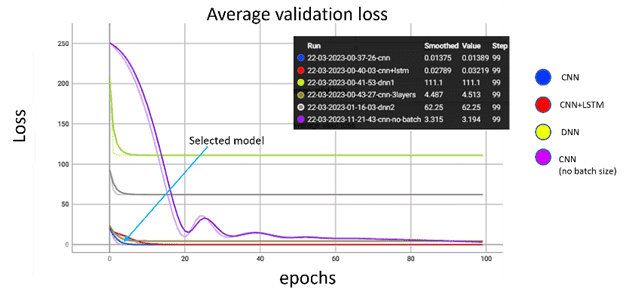
Abb. 4: Durchschnittlicher Trainings- und Validierungsverlust der verschiedenen evaluierten Modelle während 100 Epochen. Die Linie des ausgewählten 1D-CNN-Autoencoders ist dunkelblau und zusätzlich mit "selected model" gekennzeichnet. Mit einigen wenigen anderen Modellarchitekturen zeigte er einen sehr schnell zurückgehenden Verlust, was seine Auswahl als geeignetes Modell bestätigte.
Anwendung auf einen Stromverbrauchsdatensatz
Die neue Methode wurde auf einen öffentlich zugänglichen deutschen Stromverbrauchsdatensatz (German Electricity Consumption, GEM) angewandt, der auf IEEE DataPort veröffentlicht ist. Der GEM besteht aus vier Kategorien, wobei in diesem Kontext nur der zeitlich hochauflösende Datensatz verwendet wurde. Er besteht aus Daten für 98 Häuser bei einer Ablesung alle zwei Sekunden. Für einen Zeitraum von drei Jahren bestehen die Rohdaten eines jeden Hauses aus fast 144 Millionen Zeilen.
Bei maschinellem Lernen ist die Qualität der Daten einer der wichtigsten Faktoren, die sich auf die Genauigkeit und Effektivität der Modelle auswirken. Ausreißer oder Datenpunkte, die weit von den meisten Daten entfernt sind, können die Leistung von ML-Modellen beeinträchtigen. Daher ist es wichtig, solche stark abweichenden Daten in den Trainingsdaten zu identifizieren und zu entfernen. Eine Technik zur Entfernung solcher Daten ist die Hauptkomponentenanalyse (PCA) in Kombination mit dem K-Means-Clustering. Daher wurden zur Aufbereitung der Rohdaten u.a. die Genauigkeit und Konsistenz der Daten überprüft; im einzelnen auf Fehler, Inkonsistenzen oder Ausreißer, die sich negativ auf die Analyse oder Modellierung der Daten auswirken könnten.
Die PCA hilft dabei, die Dimensionalität der Daten zu reduzieren, während die Varianz erhalten bleibt, was die Visualisierung der Daten und die Erkennung von Anomalien erleichtert. Die Anomalien, die durch die PCA-Visualisierung mit Cluster-IDs aus dem K-Means-Algorithmus erkannt wurden, können dann aus den Trainingsdaten entfernt werden, was die Genauigkeit und Leistung des ML-Modells verbessern kann. Aus den so aufbereiteten Daten wurden ein Teil als Trainingsdaten und ein Teil als Validierungsdaten verwendet. Anomalien, die erkannt werden sollten, wurden im Datensatz als eine Menge von korrumpierten Spuren vorgegeben.
Fazit: Anomalieerkennung fast in Echtzeit
Das Ergebnis war, dass die Methode die Erkennung von Anomalien nahezu in Echtzeit ermöglichte. Unser neuer Ansatz zeigte sich sowohl als robust gegenüber verrauschten oder verfälschten Daten, als auch gut dazu geeignet, Anomalien in den Gesamtdaten zu klassifizieren. Dies führte zu einer Genauigkeit von 99 % bei der Erkennung von Anomalien mit nur 1,5 % falsch-positiven Ergebnissen führte. Der Satz korrumpierter Spuren wurde mit 92 % Genauigkeit klassifiziert.
Förderungshinweis
![]()
Die hier vorgestellten Ergebnisse wurden im Rahmen des vom BMBF geförderten Forschungsprojekts PROGRESSUS erarbeitet.
- Förderkennzeichen: 16MEE0003
- Förderzeitraum: 01.04.2020 bis 31.09.2023