Paketrouting für Microgrids mit ML-unterstütztem Dijkstra-Algorithmus
In diesem Beitrag soll ein Versuch zur Optimierung des Paketroutings in der Kontrollebene von Software-Defined Networking (SDN) vorgestellt werden. Die Lösung entstand als Ergebnis eines Teilarbeitspaketes des Forschungsprojektes PROGRESSUS, an dem eine Arbeitsgruppe von Ingenics Digital von 01.04.2020 bis 31.09.2023 beteiligt war, unter anderem der Autor dieses Berichts.
Die Aufgabe: Entwicklung und Validierung eines optimierten Routenfindungsalgorithmus
Mit zunehmender Verbreitung von softwaredefinierten Netzen (SDN) in der Verwaltung von Smart Grids ist auch die Notwendigkeit für effizientes Routing der Datenpakete gestiegen. Angesichts der dynamischen Energietransaktionen in Smart Grids ist optimiertes Routing eine Grundvoraussetzung für sichere und kostengünstige Datenübertragung innerhalb des vorgesehenen Zeitfensters, um eine rechtzeitige, sichere und kostengünstige Datenübertragung zu gewährleisten und so die Gesamteffizienz und Zuverlässigkeit des Energiemanagementsystems zu verbessern. SDN ermöglicht durch die Trennung der Steuerungsebene von der Datenebene ein zentralisiertes und anpassungsfähiges Netzwerkmanagement.
Der erste Ansatz: Reinforcement Learning
Der ursprüngliche Entwurf sah die Verwendung eines auf Reinforcement Learning (RL) basierenden Ansatzes für das SDN-Routing vor. Dieser Ansatz wurde als Deep Q-Network (DQN) in TensorFlow implementiert und mit der Open-AI Gym-Umgebung verbunden, einem Software-Agenten, der lernte, die Belohnungen innerhalb seiner Umgebung zu maximieren, wobei er sich speziell auf die Optimierung von Netzwerkpfaden konzentrierte. Der Agent erhielt Input in Form einer Adjazenzmatrix, die die physische Konnektivität des Netzes darstellt. Diese Matrix war binär, wobei "1" für eine Verbindung und "0" für eine fehlende Verbindung stand. Die Aufgabe des Agenten bestand darin, die effizientesten Routingpfade innerhalb eines Netzes zu ermitteln, wobei sowohl physische als auch logische Verbindungen berücksichtigt wurden. Der Aktionsraum für den DQN wurde durch mögliche Routing-Verbindungen zwischen Netzknoten definiert, die durch die bestehende physische Konnektivität bestimmt wurden. Die Belohnungsfunktion des DQN war so strukturiert, dass sie die Schaffung eines zusammenhängenden Graphen förderte, wobei die Belohnungen auf der Grundlage der Änderung der Summe der Entfernungen zwischen den Knoten und einem zentralen Controller variierten.
Trotz seines theoretischen Potenzials stieß dieser RL-basierte Ansatz auf erhebliche Herausforderungen. Ein Hauptproblem war die binäre Natur der Eingabedaten, die möglicherweise die Fähigkeit des neuronalen Netzes zur effektiven Weitergabe von Gradienten behinderte. Dies wurde durch die Untersuchung der Ausgaben des Netzes gemessen, die inkonsistent waren, oder das DQN konvergierte nicht zu einer gültigen Lösung. Mit zunehmender Größe des Netzes wuchs auch der Aktionsraum, wodurch die Komplexität der Aufgabe exponentiell anstieg. Dieses Skalierungsproblem bedeutete, dass der Ansatz für größere Netzwerke ohne erhebliche Investitionen in Ressourcen nicht durchführbar war. Die Überprüfung vieler Trainingsläufe ergab, dass das DQN selbst bei kleinen SDN-Größen nicht konvergierte. Außerdem war die Architektur des DQN möglicherweise nicht optimal für diese Aufgabe geeignet. Die Faltungsstruktur des Netzes bedeutete, dass es in erster Linie Informationen von benachbarten Knoten nutzte, ohne einen breiteren Überblick über das Netz zu haben. Diese Einschränkung deutet darauf hin, dass alternative Architekturen, wie z. B. transformatorbasierte Selbstbeobachtungsnetze, effektiver sein könnten, wenn auch um den Preis einer höheren Komplexität. Eine weitere kritische Einschränkung war die Verwendung der Adjazenzmatrix als primäre Datendarstellung. Die binäre Natur dieser Matrix bedeutete, dass die Gradientenfortpflanzung auf die Nicht-Null-Einträge beschränkt war, was möglicherweise den Lernprozess für blockierte Routen behinderte.
Neuer Ansatz: Kombination von Dijkstra mit einem heuristischen neuronalen Netzwerk à la A*
Die traditionellen Algorithmen wie Dijkstra und A* sind auf dem Gebiet der Pfadfindung mit gewichteten Graphen von grundlegender Bedeutung.
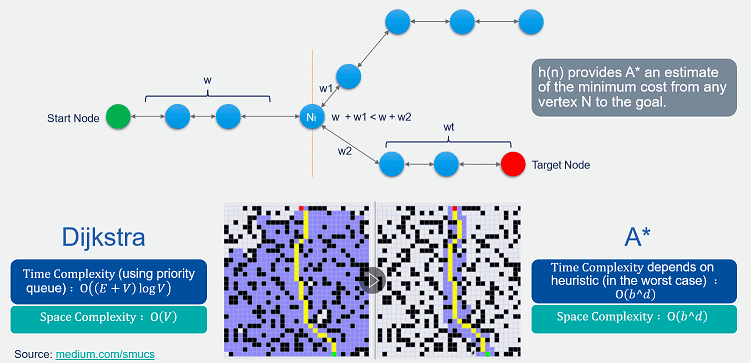
Abb. 1: Vergleich Dijkstra versus A: Der zu findende Pfad startet bei der grünen Zelle und soll zu der roten Zelle führen. Dijkstra sucht den Pfad, indem es letztlich jeden möglichen Pfad berührt (violette Zellen), bis es den kürzest möglichen Pfad zum Ziel gefunden und bestätigt hat. Dabei bezieht Dijkstra die schätzungsweise noch verbleibenden Kosten von einem aktuell berührten Knoten hin zum Zielknoten nicht ein. Das bedeutet, Dijkstra versucht von einem aktuellen Knoten auch Pfade, die gar nicht in Frage kommen können, weil sie länger als der noch verbleibende Weg zum Zielpunkt sind; Dijkstra siebt diese zu langen Möglichkeiten also nicht sukzessive aus. Das genau macht aber A, indem es die schätzungsweise noch verbleibende Distanz mit berücksichtigt und dadurch längere Pfade quasi aussiebt. Dadurch kommt A* schneller zu einer Entscheidung, welcher Pfad der kürzeste ist.
In einem dichten Netzwerk ist es jedoch entscheidend, diese Algorithmen zu optimieren, um den optimalen Pfad in kürzester Zeit zu finden. Der A*-Algorithmus stützt sich bei seiner Suche in hohem Maße auf die heuristische, also eine nach dem Versuch-und-Irrtumsverfahren vorgehende, Schätzfunktion h(n), wobei die Gesamtkosten der Kanten durch die folgende Formel bestimmt werden:
f(n)=g(n)+h(n)
Dabei sind
- f(n) die geschätzten Gesamtkosten des Pfades vom Startknoten zum Knoten n,
- g(n) sind die Kosten, um den Knoten n vom Startknoten aus zu erreichen
- h(n) sind die geschätzten Kosten vom Knoten n zum Zielknoten.

Abb. 2: Veranschaulichung der Gesamtkosten des Aufwandes, den kürzesten Pfad zu finden sowie des Verfahrens von A*, immer nur die Pfade auszuwählen, die von einem gegebenen Knoten aus am vielversprechendsten zu testen sind, da ihre Länge der geschätzten Restentfernung entspricht.

Abb. 3: Veranschaulichung wie heuristische Funktionen das Verhalten von A* beeinflussen.
In einem dichten Netzwerk steigt die Anzahl der zu berücksichtigenden Knoten und Pfade erheblich. Dies kann zu einem enorm weiten Suchraum führen (Raumkomplexität), was den Algorithmus aufgrund der hohen Rechenkosten (Zeitkomplexität) ineffizient macht. Die Entwicklung einer wirksamen heuristischen Funktion, die eine sinnvolle Unterscheidung zwischen Knoten in einem dichten Netz ermöglicht, ist eine Herausforderung. Die Heuristik muss sowohl zulässig sein (die wahren Kosten dürfen nicht überschätzt werden) als auch konsistent, was in derartigen Netzen noch schwieriger ist. Andererseits kann der Dijkstra-Algorithmus bei großen Graphen weniger effizient sein, insbesondere wenn der Graph dicht ist und eine große Anzahl von Knoten und Kanten aufweist, da er alle erreichbaren Knoten untersucht. Außerdem nutzt der Dijkstra-Algorithmus im Gegensatz zu A* keine heuristischen Informationen, um seine Suche zu leiten, was bedeutet, dass er oft mehr Pfade als nötig erkundet, was zu Ineffizienz führt. Die Kostenfunktion für Dijkstra kann wie folgt dargestellt werden:
f(n)=g(n)
Um diese Herausforderung zu bewältigen, haben wir den bisherigen Dijkstra-Algorithmus mit einem regressionsbasierten neuronalen Netzwerk als Schätzfunktion kombiniert, das sich wie A* verhält und eine Untergrenze für den Aufwand bei der Zielfindung bietet. Diese Kombination ermöglicht es dem Algorithmus, die weniger wahrscheinlich zum Ziel führenden Pfade von vorneherein auszusieben.
Anders gesagt, es wurde der traditionellen Dijkstra-Algorithmus, dem heuristische Informationen fehlen, mit einem regressionsbasierten voll verbundenen neuronalen Netz (NN) kombiniert, das als Heuristik dient. Das neuronale Netz wird überwacht trainiert, um die Kosten von einem gegebenen Knoten (n) zu einem Zielknoten zu schätzen, was effektiv als heuristische Funktion h(n) dient. Der Ansatz kann die Suche effektiver leiten und die Anzahl der Knoten, die der Dijkstra-Algorithmus untersuchen muss, reduzieren. Dieser integrierte Ansatz ahmt A* nach und bietet eine untere Schätzung der Kosten für das Erreichen des Zielknotens von jedem anderen Knoten innerhalb des Netzes aus sowie die Beschneidung von Zweigen, die weniger wahrscheinlich den optimalen Pfad ergeben. Die durch das neuronale Netz erzeugte Heuristik sollte annähernd genug sein, um die Suche zu verbessern, aber nicht so komplex, dass sie den Gesamtalgorithmus verlangsamt. Die Schlüsselidee besteht darin, ein Gleichgewicht zwischen den Kosten für die Berechnung der Heuristik und den Einsparungen bei der Sucheffizienz zu halten. Die Regression des neuronalen Netzes wird auf einem größeren Datensatz mit tatsächlichen Pfadkosten als Label trainiert, um eine effektive Heuristik zu erlernen. Dieses Training erfordert eine erhebliche Menge an Daten und Rechenressourcen.
Training des Modells und Einsatz
Das Modell des neuronalen Netzwerks wurde anhand von öffentlichen Datensätzen des OpenFlights Airport Network mit dem PyTorch Framework trainiert, die ein globales Flughafennetzwerk mit Fluglinienverbindungen zwischen Flughäfen darstellen, das aus 2905 Knoten und 15645 Kanten besteht und auf Opsahl veröffentlicht wurde (ursprünglich von OpenFlights).

Abb. 4: Veranschaulichung des zum Training verwendeten Datensatzes, die Quellen sowie die Eigenschaften des Datensatzes
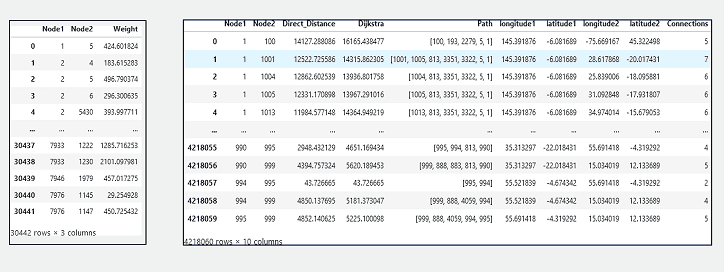
Abb. 5: Beispieldatensatztabelle mit Merkmalsspalten
Obwohl wir Flughafennetzwerke als illustratives Beispiel verwendet haben, liegt die Hauptfunktionalität in der Verbesserung des Paketroutings in SDN - der ursprünglichen Herausforderung. Im beschriebenen Ansatz wurden die ursprünglichen gewichteten Kanten des Flughafennetzwerks, die die Anzahl der Routen oder Verbindungen zwischen Flughäfen angeben, nicht direkt verwendet. Stattdessen wurden diese durch die Großkreisdistanzen zwischen zwei Knoten ersetzt, die mit der Haversine-Formel unter Verwendung der auf Opsahl veröffentlichten Flughafenattribute berechnet werden. Die Haversine-Formel gibt die Großkreisentfernungen zwischen zwei Punkten auf einer Kugel aus ihren Längen- und Breitengraden berechnet an.
Um eine überwachte Lernaufgabe mit einem neuronalen Netzwerk-Regressionsmodell zu trainieren, wurde ein Datensatz mit den Python-Bibliotheken Pandas und NetworkX erstellt. Der Datensatz stellt ein vollständig verbundenes Netzwerk eines tatsächlichen Flughafennetzwerks mit ungerichteten Kanten dar, d. h. es wird angenommen, dass jeder Knoten eines Netzwerk mit jedem anderen Knoten darin verbunden ist, so dass die endgültige Tabelle aus n(n-1)/2 Zeilen besteht. Wenn es n Knoten gibt, dann kann jeder Knoten mit (n-1) anderen Knoten in einem ungerichteten Graphen verbunden sein. Der Einfachheit halber wurde die Eingabegröße des Modells auf fünf festgelegt, darunter Elemente wie Längen- und Breitengradwerte für den Start- und den Zielknoten sowie das Kantengewicht, das diese Knoten verbindet.
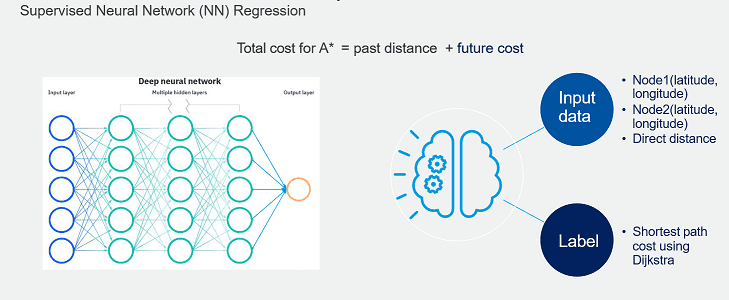
Abb. 6: Architekturmodell eines tiefen neuronalen Netzwerks (links), Berechnung der Gesamtkosten zur Auffindung des kürzestmöglichen Pfades unter Verwendung von A* (oben) sowie prinzipielles Vorgehen des Modells: Als Eingabedaten dienen zwei Knoten (Node 1, Node 2) als Start- und Zielknoten sowie die Distanz über eine lineare Verbindung dazwischen. Das Modell gibt dann die Kosten für den kürzesten Pfad mittels Dijkstra aus.
Um Labels zu erstellen, wurde der traditionelle Dijkstra-Algorithmus verwendet, um die gesamten Kantenkosten zwischen dem Start- und dem Zielknoten zu berechnen (Abb. 6). Diese berechneten Entfernungen wurden dann beim überwachten Training des neuronalen Netzwerkmodells als Labels verwendet. Die Spalten in der Tabelle von Abb. 5 veranschaulichen die verschiedenen Merkmale, die für das Training des Modells zur Verfügung stehen. Die Aufteilung des Datensatzes erfolgte mit 70, 20 und 10 Prozent für Training, Validierung und Test. Der Testdatensatz umfasst etwa zweihunderttausend Zeilen, die später zum Benchmarking der Modellleistung verwendet werden können. Schließlich wird das Modell mithilfe des PyTorch-Frameworks trainiert und mit einem K-fachen Kreuzvalidierungsdatensatz bewertet. Die Modellarchitektur in Abb. 7 zeigt ein neuronales Netz, das aus fünf vollständig verbundenen (dichten) Schichten mit ReLU-Aktivierungsfunktionen besteht, gefolgt von einer abschließenden Umformungsoperation, um die gewünschte Ausgabeform zu erreichen.

Abb. 7: Architektur eines vollständig verbundenen neuronalen Netzes. Erläuterung siehe Fließtext
Das Modell verwendet eine L1-Verlustfunktion, auch bekannt als Verlustfunktion der kleinsten absoluten Abweichungen, die für Regressionsprobleme nützlich und gegenüber Ausreißern robust ist. Ein Adam-Optimierer wurde eingesetzt, um die Gewichte des Modells iterativ auf der Grundlage von Trainingsdaten zu aktualisieren, mit einer Lernrate von 0,001 und einem Impuls von 0,9. Der Impuls trägt dazu bei, den Optimierer in die entsprechende Richtung zu beschleunigen und Oszillationen zu dämpfen. Die Eingaben des Modells werden durch jede dichte Schicht mit nacheinander der gleichen Anzahl von Einheiten (64) sequentiell verarbeitet, bevor sie auf die Ausgangsgröße umgeformt werden.
Die trainierten Modellgewichte wurden von PyTorch nach TensorFlow Lite exportiert mit insgesamt 20.000 Parametern bei einer Modellgröße etwa 55 kB, wobei Pruning- und Quantisierungstechniken angewendet werden, um Ressourcen zu sparen und eine effiziente Ressourcennutzung ohne Leistungseinbußen zu gewährleisten. Es wurde ein benutzerfreundliches Interface basierend auf ZeroMQ WebSockets entwickelt, um plattformübergreifende Kompatibilität von x86 bis zu embedded Linuxplattformen wie STM32MP157 und Raspberry Pi zu gewährleisten.
Praktischer Test: Das Modell auf dem Prüfstand
Es wurde ein spezieller Prüfstand ("Demonstrator") für Test und Vorführung der meisten Softwarekomponenten entwickelt, die von Ingenics Digital im Verlauf des Projekts PROGRESSUS entwickelt wurden (Abb. 8, 9). Der Demonstrator ist zweistufig aufgebaut:
- Virtualisierte Testumgebung auf Basis der Container-Technologie
- Test- und Demonstrationsumgebung mit physischer Hardware, auf der speziell angepasste Container laufen
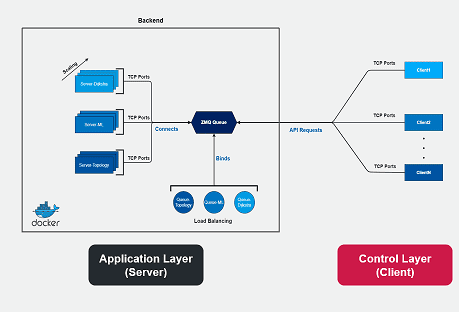
Abb. 8: Architektur des Demonstrators mit links der Application Layer (Server) sowie rechts der Control Layer (Server). Näheres siehe Text.

Abb. 9: Testaufbau für den Demonstrator, der im Wesentlichen mit einem STM32MP-basierten Single-Board-Computer mit Webinterface realisiert wurde.
Der Test in der Container-Umgebung dient der Verifizierung und Demonstration der sicheren Plug-and-Play-Funktionalität, die in der konzipierten Blockchain-basierten Architektur für den Sicherheitslebenszyklus von intelligenten Sensorknoten dargestellt ist. Diese intelligenten Sensorknoten können zur Realisierung von Smart-Grid-Funktionen verwendet werden. Der Test wurde in einer rein virtuellen Containerumgebung auf Basis von Docker-Containern durchgeführt.
Es zeigte sich, dass die skriptierte Docker-Umgebung in der Lage ist, die beschriebenen Schritte des Sicherheitslebenszyklus eines Sensorknotens erfolgreich auszuführen. Dieser Test bewies, dass das Konzept in realen Anwendungen angewendet werden kann.
Teile der Container-Umgebung wurden portiert und auf echter Hardware eingesetzt. Es wurde eine plattformübergreifende Kompatibilität sowohl für x86- als auch für eingebettete Linux-unterstützte Plattformen, wie STM32MP und Raspberry Pi, implementiert, indem eine benutzerfreundliche Schnittstelle geschaffen wurde. Diese Schnittstelle wurde mit einer Kombination aus ZeroMQ WebSockets und der Python-Bibliothek Dash entwickelt (webbasierte Datenvisualisierungsschnittstellen, Abb. 12). Darüber hinaus wird sie als Docker-Container bereitgestellt und ausgeführt, wodurch eine containerisierte Umgebung für das System bereitgestellt wird. Diese Container bieten eine Schnittstelle, über die Clients Websocket-Requests stellen können, was eine effiziente und skalierbare Kommunikation gewährleistet. Außerdem erhöht diese Einrichtung die Flexibilität und die einfache Bereitstellung.
Evaluierung der Ergebnisse
Bei der Evaluierung der mit diesem Testaufbau gewonnenen Testergebnisse zeigte sich, dass der durch das neuronale Netzwerk erweiterte Dijkstra-Algorithmus eine gegenüber dem herkömmlichen Algorithmus signifikant erhöhte Performanz erreichte im Vergleich zu dem herkömmlichen Algorithmus in Bezug auf die räumliche Suche und insbesondere anhand der Anzahl der besuchten (berührten) Knoten.
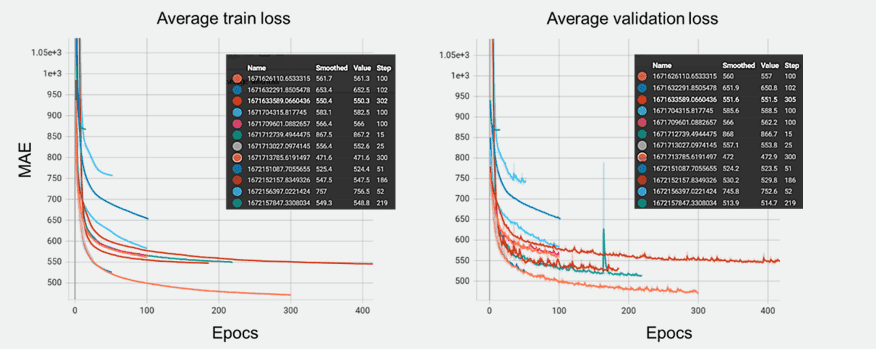
Abb. 10: Benchmarking der Leistung von neuronalen Netzmodellen mit verschiedenen Architekturen und Hyperparametern.
Abb. 10 zeigt die Ergebnisse des L1-Verlustes (mittlerer absoluter Fehler, MAE) beim Training verschiedener Regressionsmodelle für neuronale Netze, jeweils mit unterschiedlichen Architekturen und Hyperparameter-Einstellungen mit frühzeitigem Stoppen, um eine Überanpassung zu verhindern. Die linke Grafik in diesem Bild, die den Trainingsverlust darstellt, zeigt mehrere Kurven, die jeweils einer anderen Modellkonfiguration entsprechen. Diese Kurven zeigen einen gemeinsamen Trend, bei dem der Verlust zunächst stark abnimmt und sich dann abflacht, wobei einige Modelle das Plateau schneller und mit einem niedrigeren Verlustwert erreichen als andere. Dies deutet darauf hin, dass einige Konfigurationen effizienter und effektiver bei der Minimierung des Verlustes sind.
Das rechte Diagramm veranschaulicht den Validierungsverlust für dieselben Modelle. Auch hier nehmen die Kurven ab, allerdings mit bemerkenswerten Schwankungen vor allem in der zweiten Hälfte der Epochen, was darauf hindeutet, dass jedes Modell unterschiedlich gut verallgemeinert. Einige Konfigurationen zeigen Anzeichen von Überanpassung, was durch einen zunehmenden Validierungsverlust nach einer bestimmten Anzahl von Epochen angezeigt wird. Anschließend wurden die besten Modelle identifiziert und durch eine k-fache Kreuzvalidierung und frühzeitiges Stoppen feinabgestimmt, um Robustheit zu gewährleisten und Überanpassung zu vermeiden, was zu einer stabileren Leistung führte.
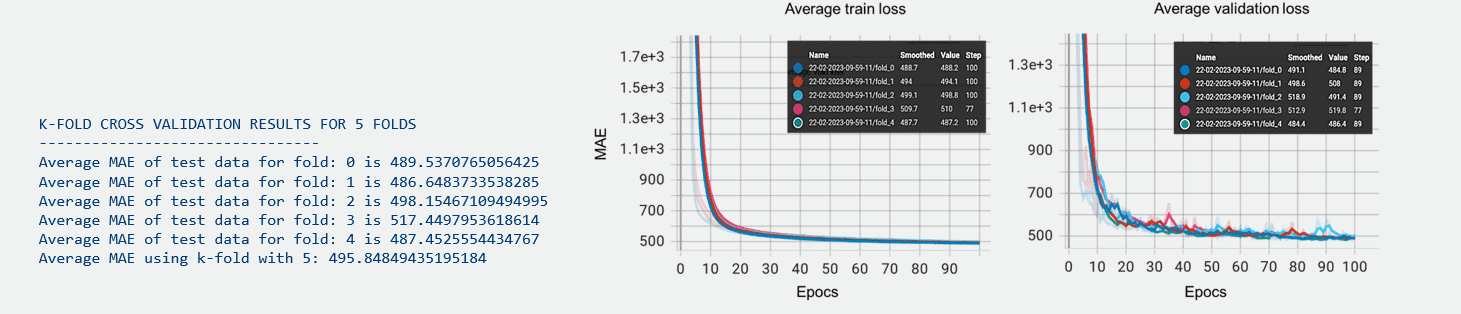
Abb. 11: Durchschnittlicher Trainings- und Validierungsverlust bei K-facher Kreuzvalidierung mit K=5 für die ausgewählte Modellarchitektur.
Die Diagramme in Abb. 11 zeigen ähnliche Diagramme wie zuvor, jedoch für eine ausgewählte Architektur eines neuronalen Netzes, wie in Abb. 7 dargestellt, die mittels 5-facher Kreuzvalidierung über 100 Epochen trainiert und validiert wurde. Die überlagernden Linien in jedem Diagramm zeigen die Leistung des Modells über die fünf verschiedenen Kreuzvalidierungsfalten an, wobei die Konvergenz dieser Linien auf eine konsistente Verringerung des Verlusts über alle Falten hindeutet. Der Abwärtstrend ohne anschließenden Anstieg deutet darauf hin, dass die Modelle gut verallgemeinern und sich nicht übermäßig anpassen. Dies wäre offensichtlich, wenn der Validierungsverlust zu steigen beginnen würde, während der Trainingsverlust weiter sinkt. Die Sondierungsphase der Modellauswahl wird zuerst durchgeführt, wobei verschiedene Architekturen und Hyperparameter über eine größere Anzahl von Epochen getestet werden.
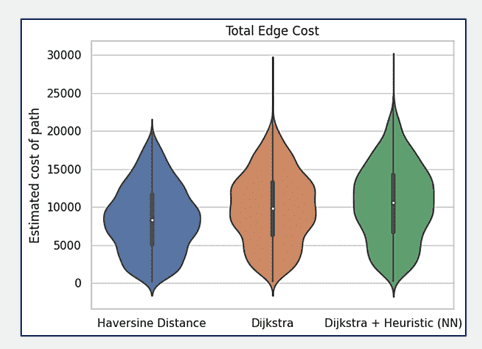
Abb. 12: Auswertung der Modelleffizienz unter Verwendung von 3000 Stichproben basierend auf der Exploration des Suchraums. Vergleichend werden die Verteilungen geschätzter Kosten dargestellt, die über drei verschiedene Methoden gefunden wurden. Näheres siehe Text.
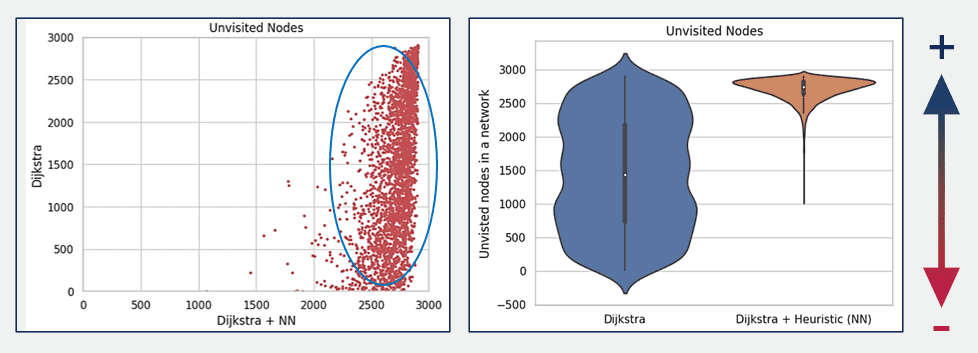
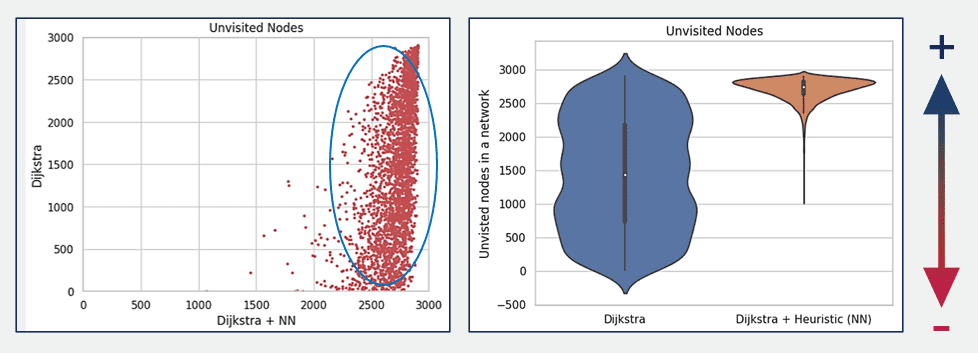
Abb. 13: Scatter und Geigen-Plots, welche die Anzahl der nicht besuchten Knoten eines Netzwerks für zwei verschiedene Fälle vergleicht, in denen jeweils die optimale Entfernung zwischen zwei Knoten gefunden werden sollte.
Abb. 12 und 13 zeigen die Geigen- und Boxplots, in denen die Leistung des klassischen Dijkstra-Algorithmus mit einer Variante von Dijkstra verglichen wird, die ein neuronales Netz als Heuristik verwendet, basierend auf 3000 Stichproben des Testdatensatzes. Das Diagramm zeigt drei Verteilungen für die geschätzten Pfadkosten: eine für die Haversine-Distanz (blau, links), eine für den klassischen Dijkstra (orange, mittig) und eine für Dijkstra mit dem neuronalen Netz (grün, rechts). Die Streuung der Datenpunkte zeigt die Variabilität der gesamten Pfadkosten über die Stichproben hinweg, wobei Dijkstra mit Heuristik eine kompaktere Verteilung aufweist, was auf konsistentere Pfadkosten bei Anwendung der Heuristik des neuronalen Netzes hindeutet. Die Effektivität der Heuristik des neuronalen Netzes, die Pfadkosten nicht zu unterschätzen, kann auf ihre Fähigkeit zurückgeführt werden, aus den Daten zu lernen, mit denen sie trainiert wurde. Die rechte obere Grafik konzentriert sich auf die Gesamtzahl der nicht besuchten Knoten im Netz, nachdem die Algorithmen den optimalen Pfad gefunden haben. Der klassische Dijkstra-Algorithmus weist eine größere Streuung bei der Anzahl der nicht besuchten Knoten auf, was eine größere Variabilität in der Leistung bedeutet.
Im Gegensatz dazu weist der Dijkstra-Algorithmus mit Heuristik (grün, rechts) eine deutlich engere Verteilung mit einem höheren Median der Anzahl der unbesuchten Knoten auf, was darauf hindeutet, dass er mehr Knoten unbesucht lässt. In unserem Ansatz wurde die Leistung des Modells auf der Grundlage der Anzahl der nicht besuchten Knoten bewertet, wobei davon ausgegangen wird, dass eine höhere Anzahl von nicht besuchten Knoten zu bevorzugen ist. Dieses Kriterium deutet darauf hin, dass der Dijkstra-Algorithmus mit Heuristik im Vergleich zum klassischen Dijkstra-Algorithmus besser abschneidet, da er zu einer größeren Anzahl unbesuchter Knoten führt. Dies könnte einen effizienteren Pfadfindungsprozess implizieren, indem ein optimaler Pfad gefunden wird ohne ebensoviele alternative Pfade berührt werden. Es kann allerdings sein, dass der Dijkstra-Algorithmus mit dem neuronalen Netzwerk vergleichbare oder etwas höhere Kosten verursacht wie der klassische Dijstra-Algorithmus.
Fazit der Tests: Ein vielversprechender Ansatz
Durch die Kombination des leichtgewichtigen neuronalen Netzwerks als Schätzfunktion mit dem bewährten Pfadfindungsalgorithmus bietet unser Ansatz demnach eine dynamische und effiziente Strategie für das Paketrouting in der Kontrollebene eines SDN. Dieser Entwicklungsschritt bietet auf breiter Front Möglichkeiten für den Smart Grid-Sektor, insbesondere für solche, die dichte Netzwerke verwenden.
Förderungshinweis
![]()
Die hier vorgestellten Ergebnisse wurden im Rahmen des vom BMBF geförderten Forschungsprojekts PROGRESSUS erarbeitet.
- Förderkennzeichen: 16MEE0003
- Förderzeitraum: 01.04.2020 bis 31.09.2023